Yet Another DeepSeek Overview
R package build / 2025-02-08
The release of DeepSeek-R1, a Chinese open-weight language model, in January 2025 sent shockwaves through the tech industry, triggering a stunning $1 trillion loss in US stock market value in a single day. For the first time in a few years, an open-weight model has demonstrated the capability to rival proprietary giants like OpenAI’s GPT models. Not only does it offer competitive performance, but it also achieves this using older GPUs than Western labs due to US export restrictions.
R1 utilizes many optimization strategies for efficiency, and also has a unique training strategy for reasoning. Unlike most recent LLMs, which rely heavily on post-training using labelled data, DeepSeek-R1 has demonstrated remarkable reasoning abilities through verifiable rewards alone.
This breakthrough didn’t happen overnight. Over the past year, 15 research papers have laid the foundation for R1’s capabilities. While this blog won’t cover all of them, we’ll explore the most critical aspects that explain how R1 came to be.
Timeline
January 5, 2024 – DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Mostly reproduces LLaMA 2 but with more of a focus on Chinese, which leads to a much different tokenizer. The layer counts are slightly different from LLama 2, during pre-training they use a different scheduler, and for preference alignment they use DPO instead of PPO like LLama 2.
Shows their own scaling laws in terms of non-embedding FLOPs/token rather than rather than using parameter count like Chinchilla vs. GPT-3 approaches, which also provide differing ratios.
Emphasizes data curation and shows that higher-quality data leads to more effective scaling.
January 11, 2024 - DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Introduces fine-grained expert segmentation, which uses many small experts rather than a few larger ones as used in other models like Mixtral/GShard
Instead of only expert models as in Mistral/GShard, they have a shared general expert which is always active
Introduces an auxilliary loss for load balancing across experts and devices. However, this is likely not commonly done and DeepSeek themselves later remove in V3 because an addition to loss can interact with LLM training behaviour.
April 27, 2024 - DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Focus on reinforcement learning: Introduces a new technique called Group Relative Policy Optimization (GRPO), which similar to PPO but without the need for a critic model.
Shows that their new method is part of a general RL framework containing other methods like PPO, DPO, and RFT.
May 7, 2024 – DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Introduce Multi-Latent Attention (MLA) for compressing the KV-Cache
Uses MoE architecture introduced in DeepSeekMoe
Applies YaRN for extending context length to 128k
December 27, 2024 – DeepSeek-V3 Technical Report Detailed DeepSeek-V3, a 671B-parameter Mixture-of-Experts model with 37B parameters active per token.
- Introduce multi-token prediction
- Uses auxilliary-loss free load-balancing for MoE introduced by DeepSeek in a recent paper along with a sequence auxilliary-loss
- Infrasructure improvement for efficiently using older GPUs
- Mostly uses architecture similar to DeepSeek-V2 (MoE with MLA and GRPO)
January 22, 2025 – DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeekSeek-R1-Zero: First open-source model to show models can learn to reason with RL with verifiable rewards alone, without SFT or learned reward model
- DeepSeek-R1: A multi-stage training pipeline including some SFT improves readibility and reasoning
- Performance comparable with GPT-4o-0513 and Claude-3.5-Sonnet-1022
- Many infrastructure optimizations
DeepSeekMOE
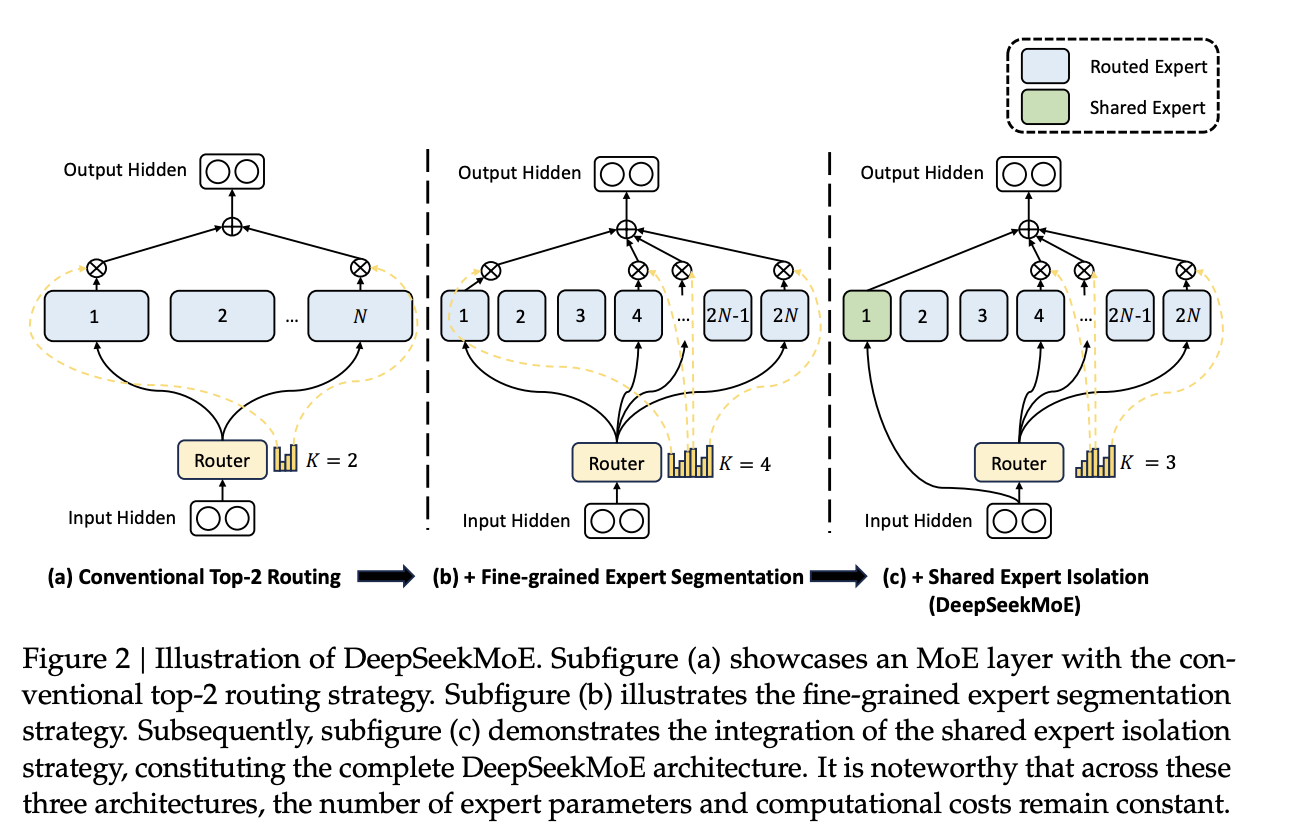
In Mixture-of-Expert (MoE) language models, the FFNs in transformer blocks are substituted with MoE layers. This contains multiple “expert” sub-networksand a learned gating function to select or weight each expert.
Conventional MoE
Usually Moe architectures (eg. GShard, Mixtral) activate the top-𝐾 of 𝑁 experts. They have a small number (eg. 8) of large experts. These face the following challenges,
Knowledge Hybridity: Since there are only a few experts, each tend to cover diverse skills and knowledge. So we don’t actually end up with specialized experts, and the diverse knowledge in each is hard to utilize simultaneously.
Knowledge Redundancy: Multiple experts activated at once may need some shared knowledge, so they can converge to learning shared knowledge. This creates redundancy in learned parameters.
DeepSeekMoe
DeepSeekMoe address the issues in conventional Moe architectures in 2 main ways,
Fine-Grained Expert Segmentation: With the same number of parameters, create smaller and more experts. Keeping the same nummber of active parameters, can have more active experts. Each expert is more specialized, and can have more fine-grained combinatorial flexibility over combination of experts. while maintaining
Shared Expert: A few experts are always active, i.e., shared across all tokens. These are meant to capture common knowledge needed across various domains. This reduces redundancy in the specialized experts.
Validation
The following DeepSeekMOE architecture was trained on 100B tokens from a diverse multi-lingual corpus,
- Total params: 2B
- Active params: 0.3B
- All FFNs replaced with MOE layers
- Total expert parameters = 16 X standard FFN
- All active expert parameters (including shared expert) = 2 X standard FFN
- Tokenizer with 8K vocabulary
- 9 transformer layers and hidden dimension 1280
- 10 attention heads, each dead dimension of 128
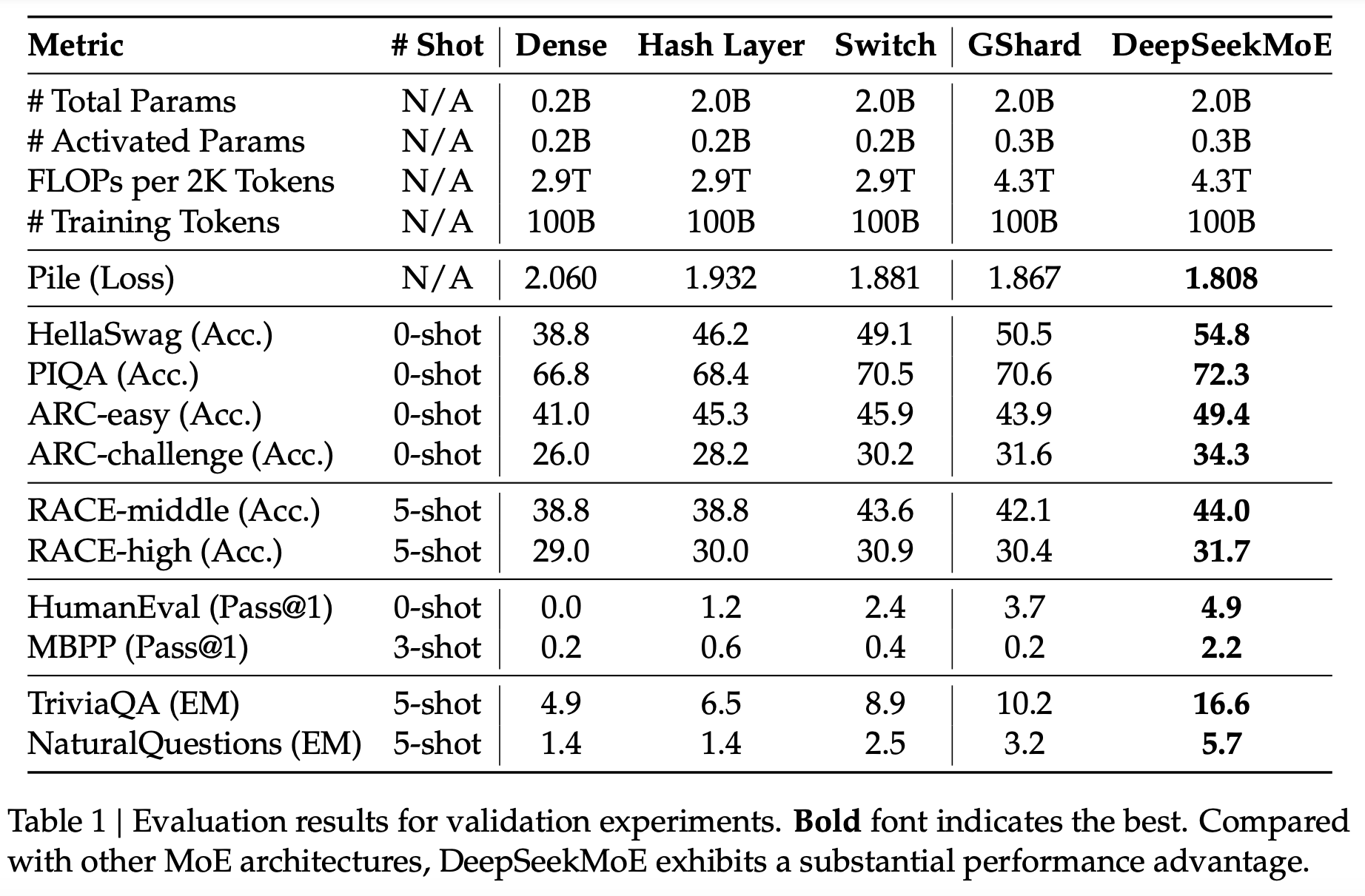
- From the results above we see that DeepSeeKMoe performs better than GShard with same number of total and activate parameters.
- Also performs better than other MoE baselines with same total parameters but slightly lower activate parameters (not sure why different amount was activated)
- DeepSeekMoe performs better than a dense baseline with total parameters equal to total active parameters in DeepSeekMoE (seems obvious)
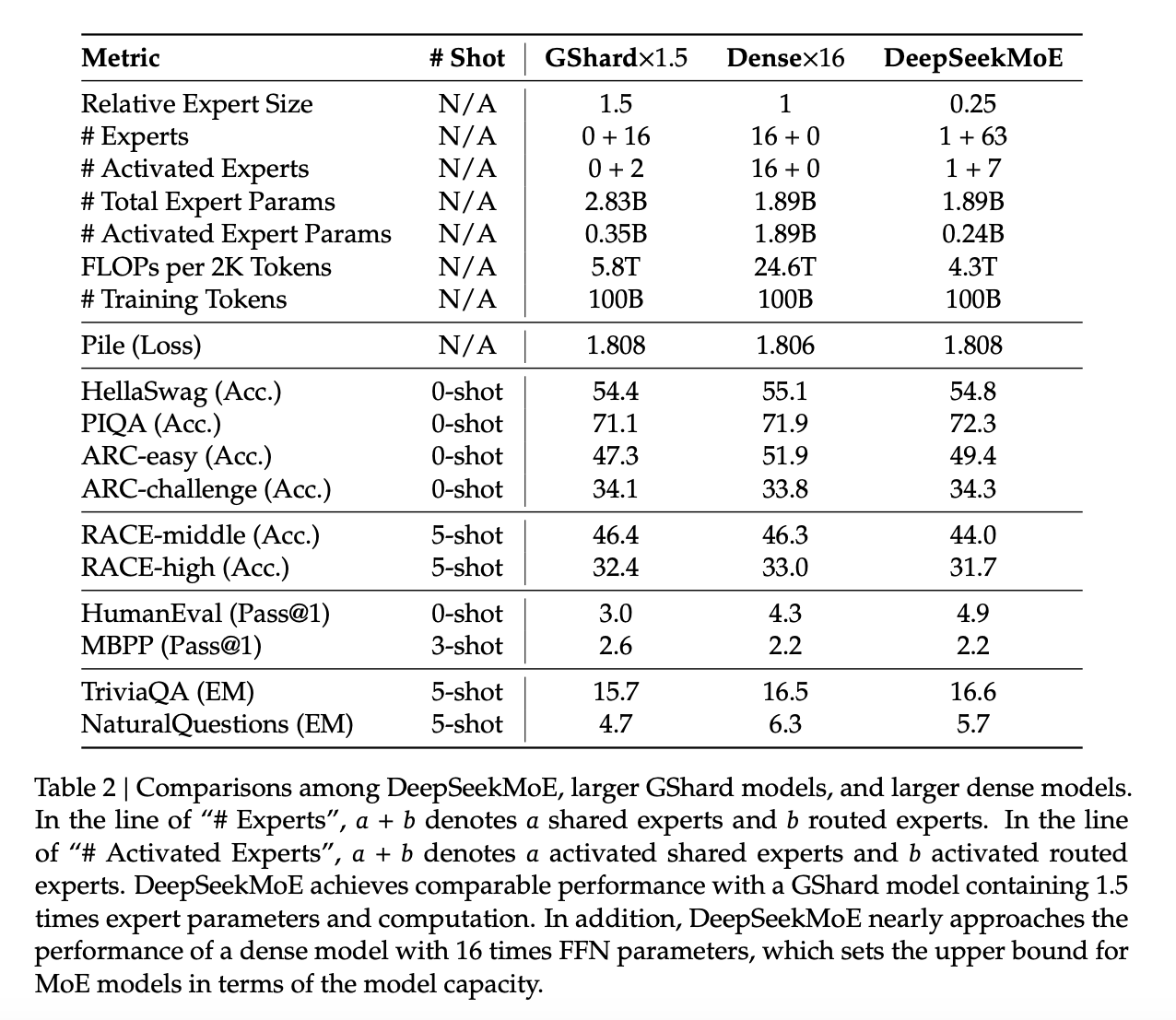
Dense Upper Bound
- Dense and Moe with same total parameters
- MoE performs close to Dense (the uppser bound)
Ablations
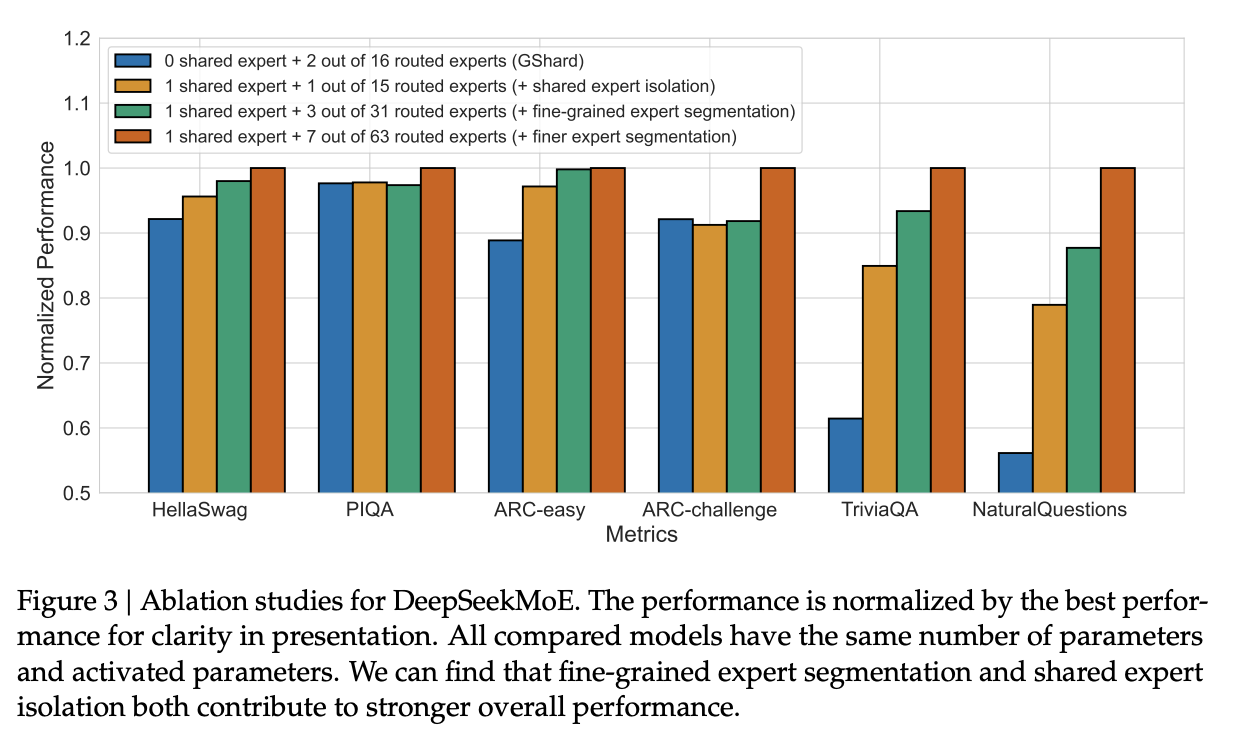
- No shared expert performs worse across majority benchmarks
- With 1/8th active experts, finer-grained experts leads to better performance
- Ratio of routed and shared experts didn’t have significant effects, but found 1:3 ratio of shared to routed to be best on Pile loss
Expert Specialization
Redundancy
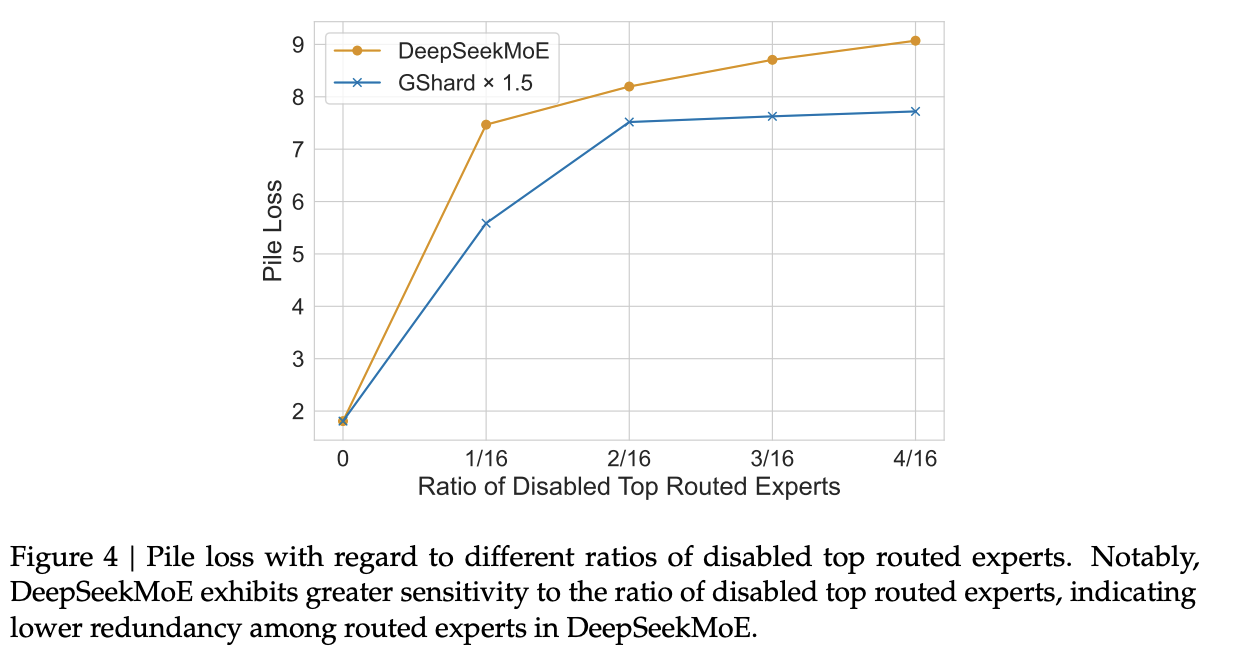
To check redundancy, different proportions of top routed experts are disabled and top K experts chosen without them. Pile loss increases and is higher than baseline (Gshard X1.5), suggesting experts are irreplacable (Fig 4).
Accuracy of Knowledge
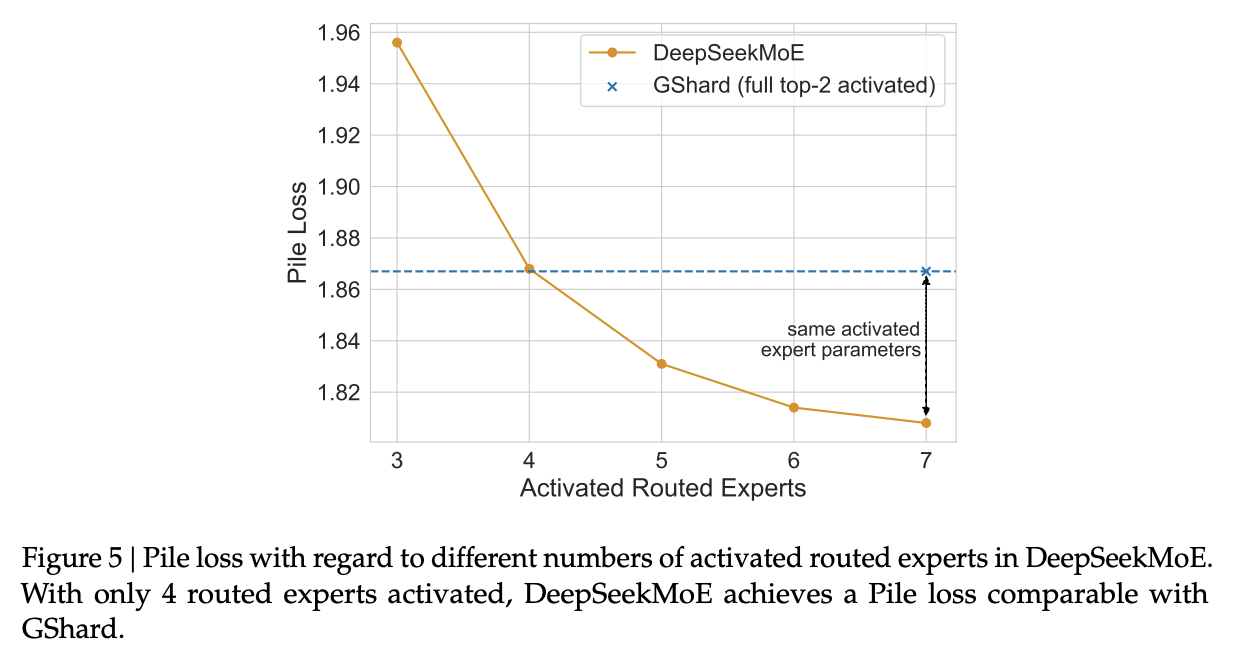
- Vary number of activated routed experts from 3-7, and compare to GShard with same numer activated parameters as DeepSeekMoe with 7 active. DeepSeekMoE can get same performance to GShard with only 4 active experts (Fig 5).
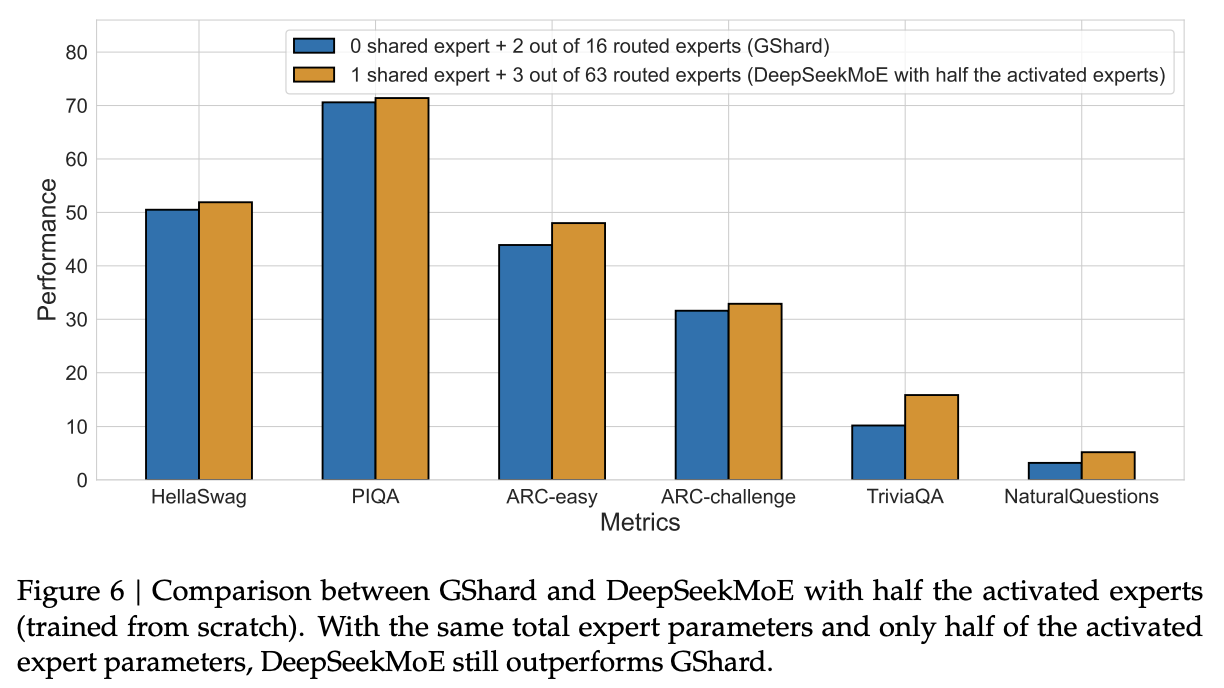
- Train from scratch and compare with GShard with same total parameters but double the number of active parameters. DeepSeekMoe still performs better than GShard (Fig 6)
Scalability
16B
- Total 16B parameters, and 2.8 activate parameters
- All FFNs except in first layer are MoE, because of convergence issues
- Each MoE layer:
- 2 shared experts and 64 routed experts
- each expert = 0.25 * standard FFN parameters
- 6 active routed experts
- 28 Transformer layers with hidden dimension to 2048.
- 16 attention heads with head has a dimension of 128
Internal Baseline
- Compare to DeekSeek-7b-dense
- Both trained from scratch on 2T tokens
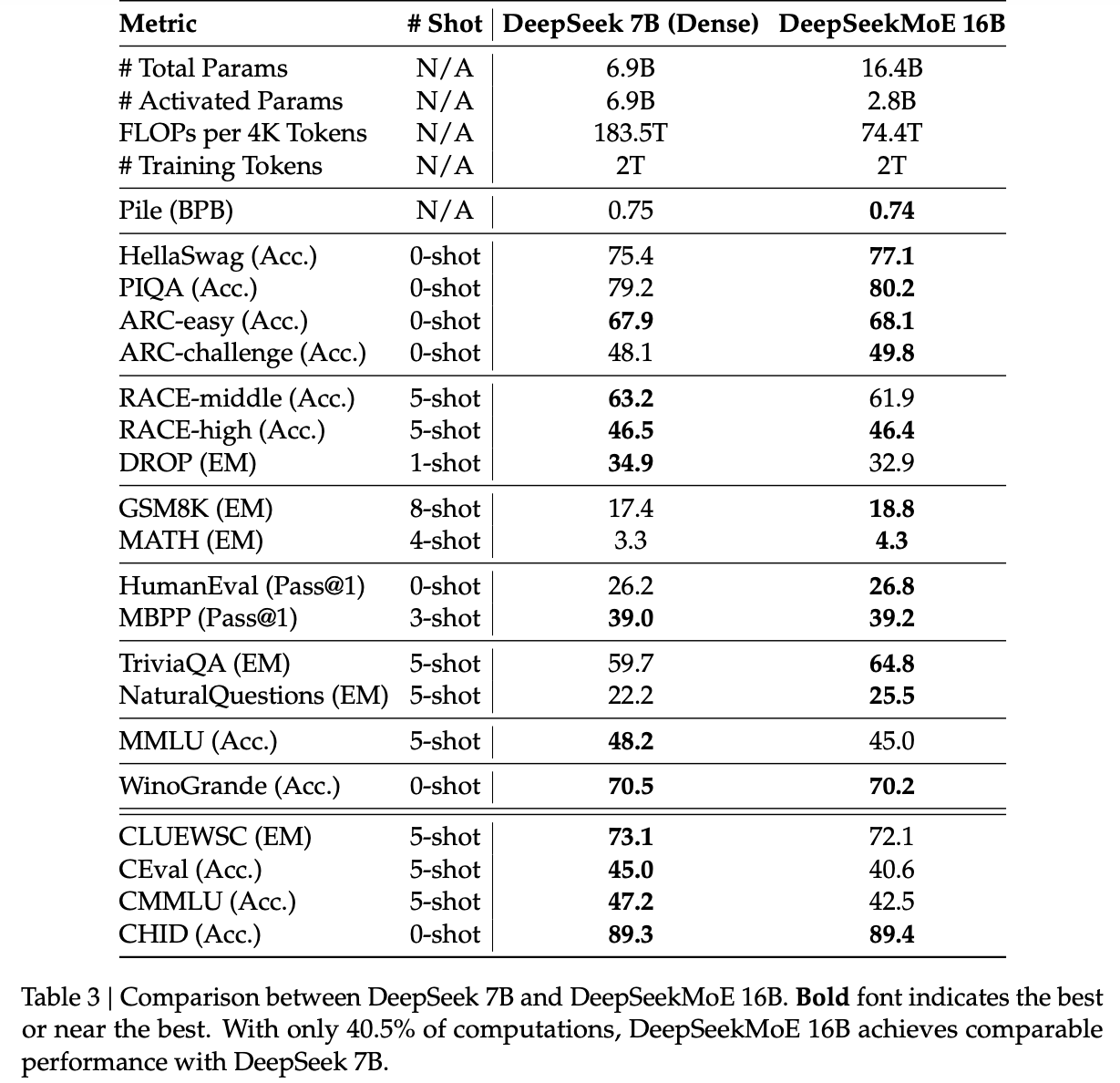
- DeepSeekMoE-16B has 40% less computations than DeepSeek-7b-dense but comparable performance
- DeepSeekMoE 16B is strong in language modeling and knowledge-intensive tasks such as Pile, HellaSwag, TriviaQA, and NaturalQuestions. This is in line with the hypothesis that FFNs in transformers memorize knowledge (MoE FFN parameters > attention paramters) Explain futher?
- DeepSeekMoE limitated in addressing multiple-choice tasks, maybe due to fewer attention parameters
LLaMA2-7B
Comparable performance with LLaMA2 7B, which has ~2.5 times the active parameters that DeepSeekMoe-16b has.

DeepSeekMath
Focus on reinforcement learning: Introduces a new technique called Group Relative Policy Optimization (GRPO), which similar to PPO but without the need for a critic model.
Shows that their new method is part of a general RL framework containing other methods like PPO, DPO, and RFT.
Group Relative Policy Optimization (GRPO)
Group Relative Policy Optimization (GRPO) modifies PPO by removing the separate value function (critic) network and instead uses a group-based baseline for policy updates. In practice, multiple responses are sampled for each prompt, and the average reward of these responses serves as a baseline to compute advantages for the policy update. Traditionally, the value function measures the expected reward of the current generation from the policy. Conceptually, now this is being replaced by the average actual reward from multiple generations from the policy, i.e., a type of expected reward.
Removing the value function helps by,
Reducing computational cost, since it is usually another model of comparable size to the policy
Avoid training instability. There can be issues associated with the value being assigned at the last token, and the value function can be trcky to train for language (perhaps something to do with the structure of language)
GRPO optimizes the following policy,
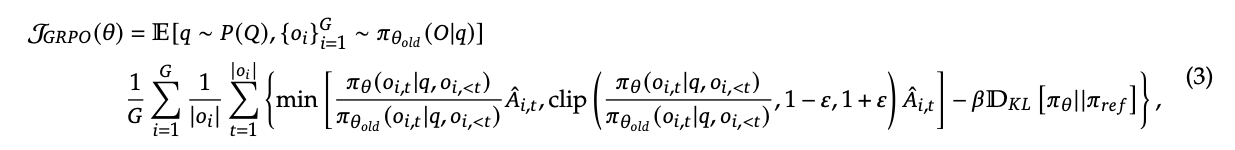
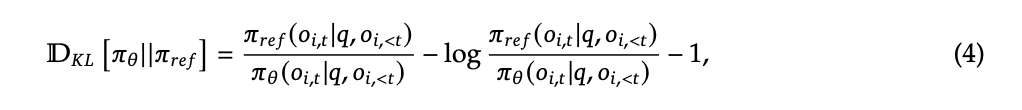
Advantage Computation
The advantage is computed in two ways,
- Outcome Supervision: For each question \(q\), a group of outputs \(\{ o_1, o_2, \dots, o_G \}\) is sampled from the old policy \(\pi_{\theta_{\text{old}}}\). A reward model assigns scores \(r = \{ r_1, r_2, \dots, r_G \}\) to these outputs. The rewards are then normalized by subtracting the group mean and dividing by the standard deviation to create the advtange:
\[ \hat{A}_{i,t} = \tilde{r}_i = \frac{r_i - \text{mean}(r)}{\text{std}(r)} \]
- Process Supervision: A single reward at the end of each output may be insufficient for complex reasoning tasks. Process supervision which provides a reward at the end of each reasoning step, thus providing denser supervision during training. Given a question \(q\) and \(G\) sampled outputs \(\{ o_1, o_2, \dots, o_G \}\), a process reward model scores each step, producing stepwise rewards:
\[ R = \left\{ \{ r_{\text{index}(1)}^1, \dots, r_{\text{index}(K_1)}^1 \}, \dots, \{ r_{\text{index}(1)}^G, \dots, r_{\text{index}(K_G)}^G \} \right\} \]
where \(\text{index}(j)\) is the end token index of step \(j\), and \(K_i\) is the total number of steps in output \(i\). These rewards are then normalized:
\[ \tilde{r}_{\text{index}(j)}^i = \frac{r_{\text{index}(j)}^i - \text{mean}(R)}{\text{std}(R)} \]
The advantage for each token is computed as the sum of normalized rewards from that token’s step onward:
\[ \hat{A}_{i,t} = \sum_{\text{index}(j) \geq t} \tilde{r}_{\text{index}(j)}^i \]
Iterative RL with GRPO
As reinforcement learning progresses, the old reward model may become insufficient for supervising the evolving policy. To address this, iterative GRPO is employed:
- New training data for the reward model is generated from the latest policy samples.
- The reward model is continually updated using a replay mechanism that retains 10% of historical data.
- The reference model is reset to the current policy, and the policy is further trained with the updated reward model.
This iterative process ensures the reward model remains aligned with the evolving policy.

Unified RL Framework
Many RL methods can be seen as specialized cases of the following unified framework,
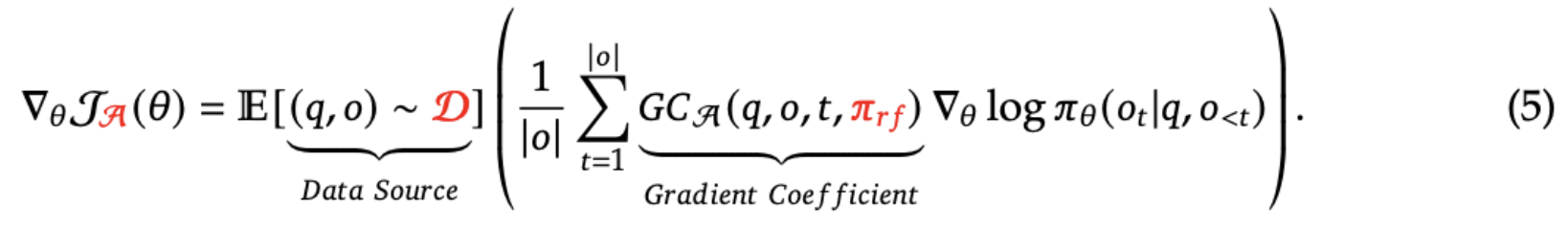
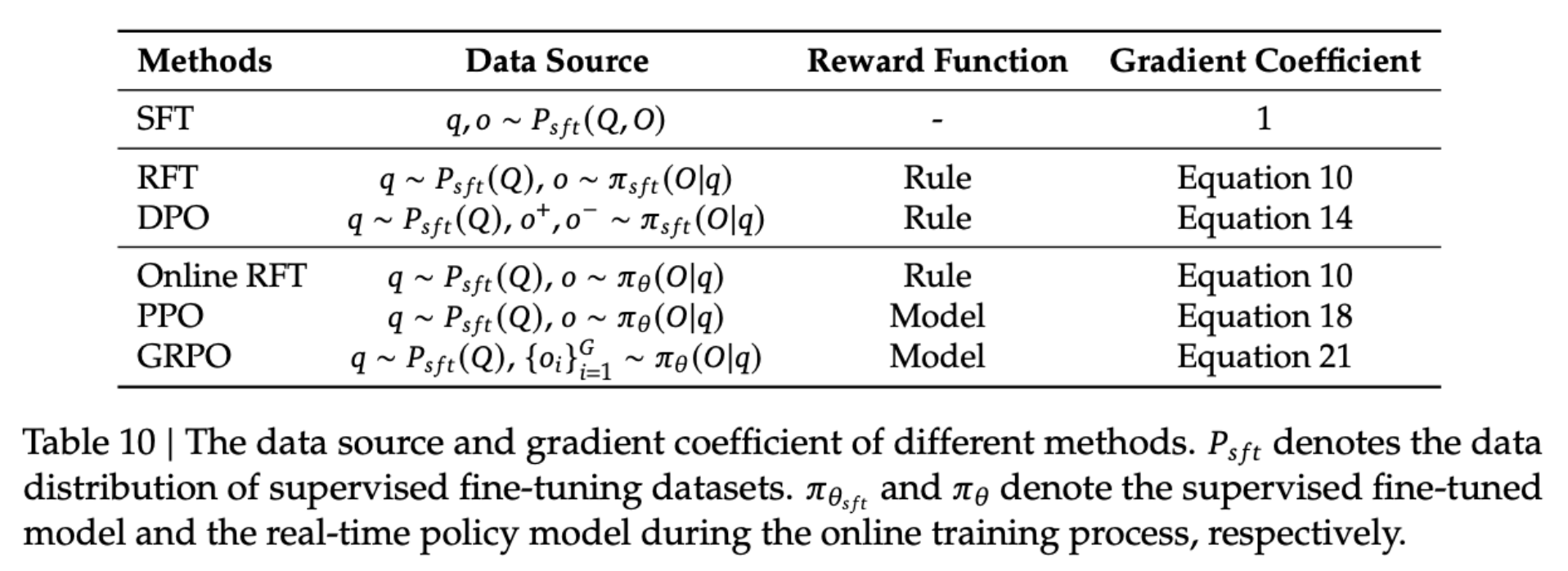
PPO
The advantage function in PPO is computed using Generalized Advantage Estimation (GAE), which uses a reward model and a learn value function.

RFT & Online RFT


Results
RL Ablation: SFT VS RL
RL improves Pass@K but not Maj@K. So it is pushing the right answer to the top and making the distribution fundamentally more robust, but not making the model fundamentally better Page 21, not understsanding the framing and implication well here, like what does fundamentally better mean?

RL Ablation: RFT VS RL
Offline RFT performs similar to online methods early on when the SFT reference model is closer to the updated policy model. However, as training progresses , offline methods lag in performance because offline sampling do not represent the current policy as well.
GRPO methods perform better than Online RFT, even though both sample from current policy. This is because GRPO uses a reward model so can score individual instances at granular magnitues, whereas Online RFT can only award 1 for correct and 0 for incorrect.
Process supervision performs better than outcome supervision for GRPO, demonstrating that more fine-grained, reasoning step-aware gradient coefficients are helpful.
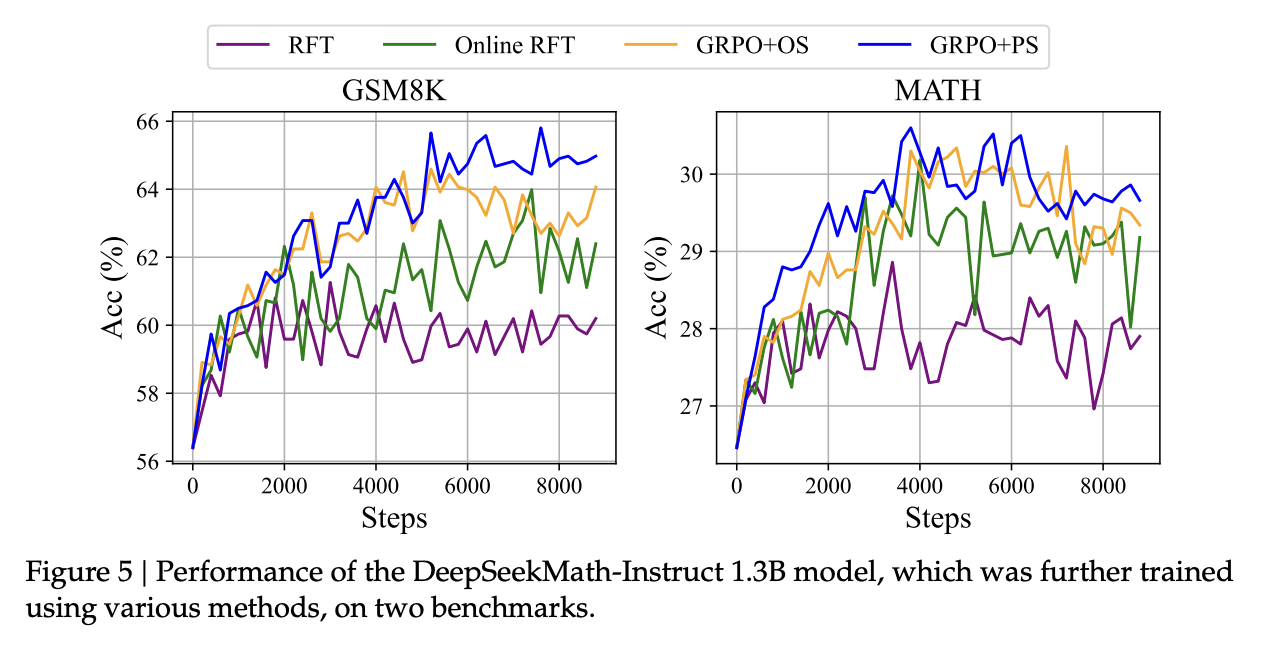
Iterative RL
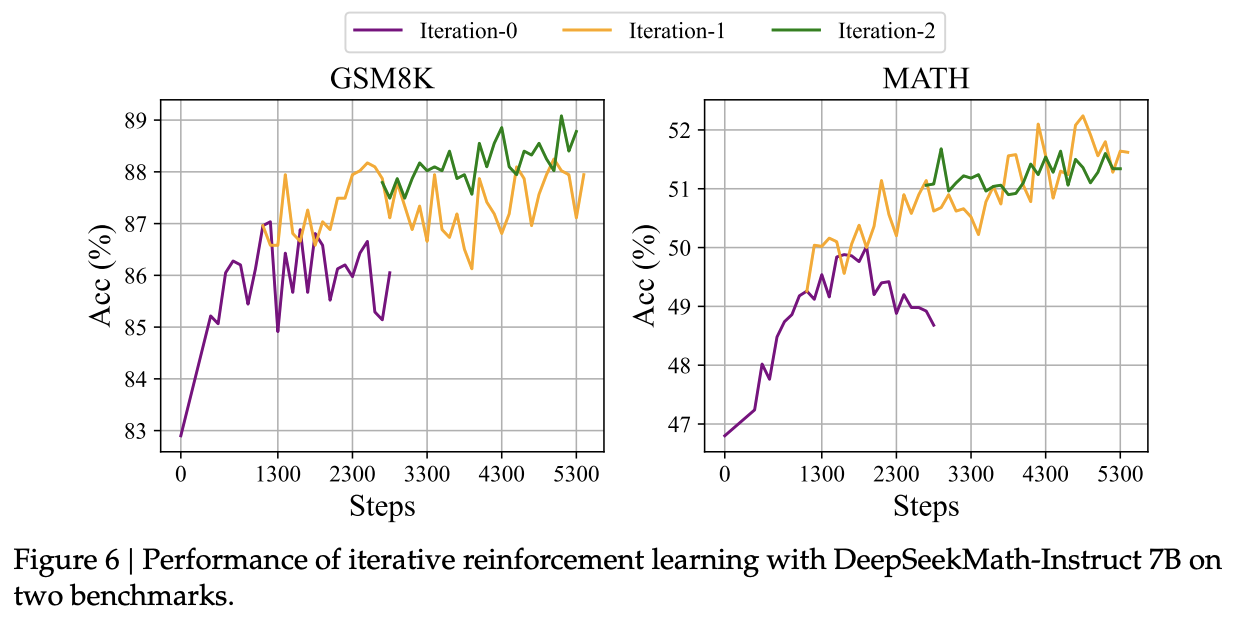
Comparison with Other LLMs
Two DeepSeekMath Models are used,
DeepSeekMath-Insruct: SFT mathematical instruction tuning
DeepSeekMath-RL: GRPO on DeepSeekMath-Insruct. Presumably with process supervision and iterative RL since they performed best in ablations (Ques: Is this confirmed in the paper?)
DeepSeekMath-RL performs better than all baselines across math reasoning benchmarks.
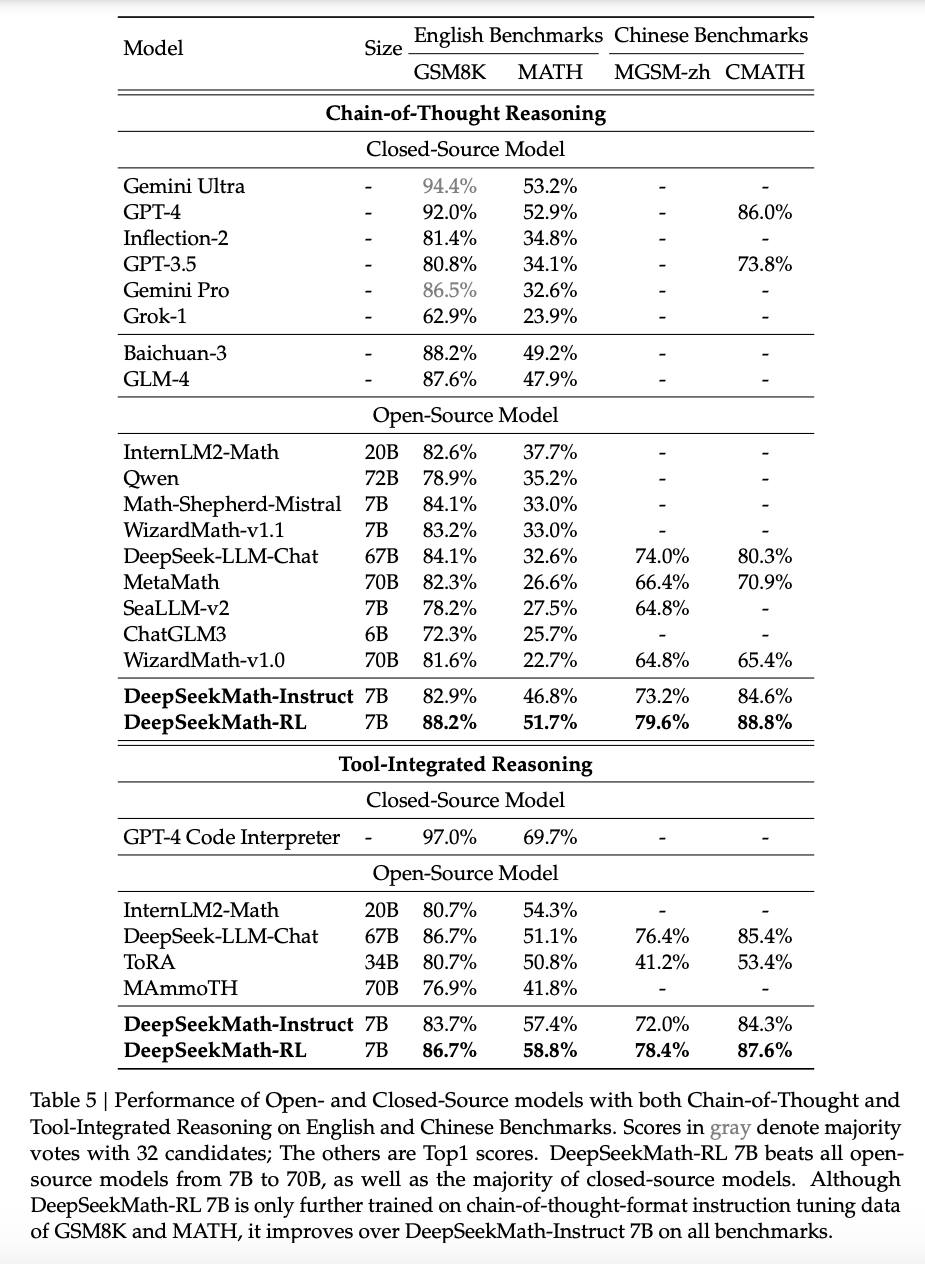
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Introduce Multi-Latent Attention (MLA) for compressing the KV-Cache
Uses MoE architecture introduced in DeepSeekMoe
Applies YaRN for extending context length to 128k
Introduce Multi-Latent Attention (MLA) for compressing the KV-Cache
Uses MoE architecture introduced in DeepSeekMoe
Applies YaRN for extending context length to 128k
Multi-Latent Attenion (MLA)

In standard MHA, the input embedding, \(h\), to the attention mechanism is projected to keys, values, and queries, which are then slices into sub- keys, values, and queries for the various heads. However, attention is both memory- and compute-intensive. The KV cache can be a big bottleneck for sequence length and batch size.
In MLA, the K,V, and Qs are compressed, starting by projecting \(h\) a bit differently.
- The input embedding, \(h\) is projected to a joint compression of keys and values, \(c^{kv}\), using \(W^{DKV}\)
- The input embedding, \(h\) is projected to a compressed query, \(c^Q\), using \(W^{DKV}\)
- The jointly compressed \(c^{kv}\) is up projected to keys, \(K^C\), using \(W^K\) and into values, \(V^C\) using \(W^V\)
- The compressed query is up projected to queries using \(W^Q\)
RoPE
Rotary Positional Embedding (RoPE) integrates positional information by applying a position dependent rotation to query and key vectors in the attention mechanism. Concretely, for a token at position \(n\), each 2D-subspace \(\left(x_{2 j}, x_{2 j+1}\right)\) of a query or key vector is rotated by an angle \(\theta_n\), yielding: \[ \binom{x_{2 j}^{\prime}}{x_{2 j+1}^{\prime}}=\left(\begin{array}{cc} \cos \theta_n & -\sin \theta_n \\ \sin \theta_n & \cos \theta_n \end{array}\right)\binom{x_{2 j}}{x_{2 j+1}} . \]
Here, \(\theta_n\) grows with the token’s position \(n\), ensuring the model learns both absolute and relative positional relationships in a flexible, extendable way.
RoPE is not applied to the upprojected keys and queries. Instead, decopuled rotary position queries, \(Q^R\) and keys,\(K^R\), are created, which are concetenated to \(Q^C\) and \(K^C\) to create the final keys and quries for the attention mechanism. The RoPE key is shared across heads.
Why Decoupled? If RoPE is applied directly to \(K^C\), then during inference these keys woud have to be materialized. But for efficiency, they don’t actually materialize the keys. Instead, this can be done,
\[ \begin{aligned} q_{\text {new }}^{\top} k_t & =\left(W_Q h_{\text {new }}\right)^{\top}\left(W_{U K} c_{K V_t}\right) & & (\text { Standard query-key dot product) } \\ & =\left(W_{U K}^{\top} W_Q h_{\text {new }}\right)^{\top} c_{K V_t} \end{aligned} \]
However, the RoPEd keys do need to be computed and cached during inference, but think they may be smaller so its not as expensive.
Results
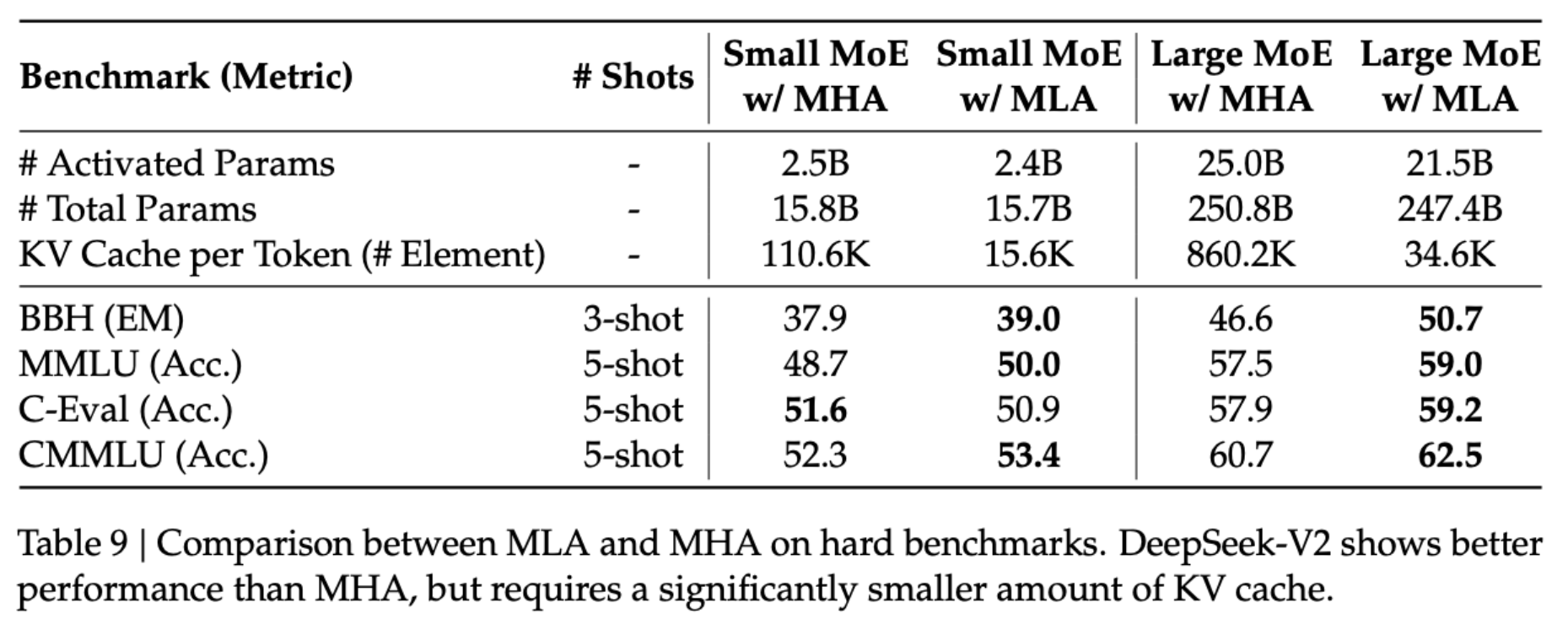
MLA performing even better than MHA on most of these seems weird.
DeepSeek-V3 Technical Report
- Introduce multi-Token prediction
- Uses auxilliary-loss free load-balancing for MoE introduced by DeepSeek in a recent paper along with a sequence auxilliary-loss
- Infrasructure improvement for efficiently using older GPUs
- Mostly uses architecture similar to DeepSeek-V2 (MoE with MLA and GRPO)
Multi-Token prediction (MTP)
Multi-token prediction was introduced in Meta’s Better & Faster Large Language Models via Multi-token Prediction, where the output later of a language model is replaced with n output heads for predicting n future tokens. In contrast, here use auxilliary “MTP Modules” (like additional layers) for predicting n future tokens.
This may improve data efficiency but that’s not the goal here. The goal here is improved representations, because MTP enables pre-planning for tokens further ahead. Here sequentially predict additional tokens and keep the complete causal chain at each prediction depth. During inference the additional MTP modules are removed.
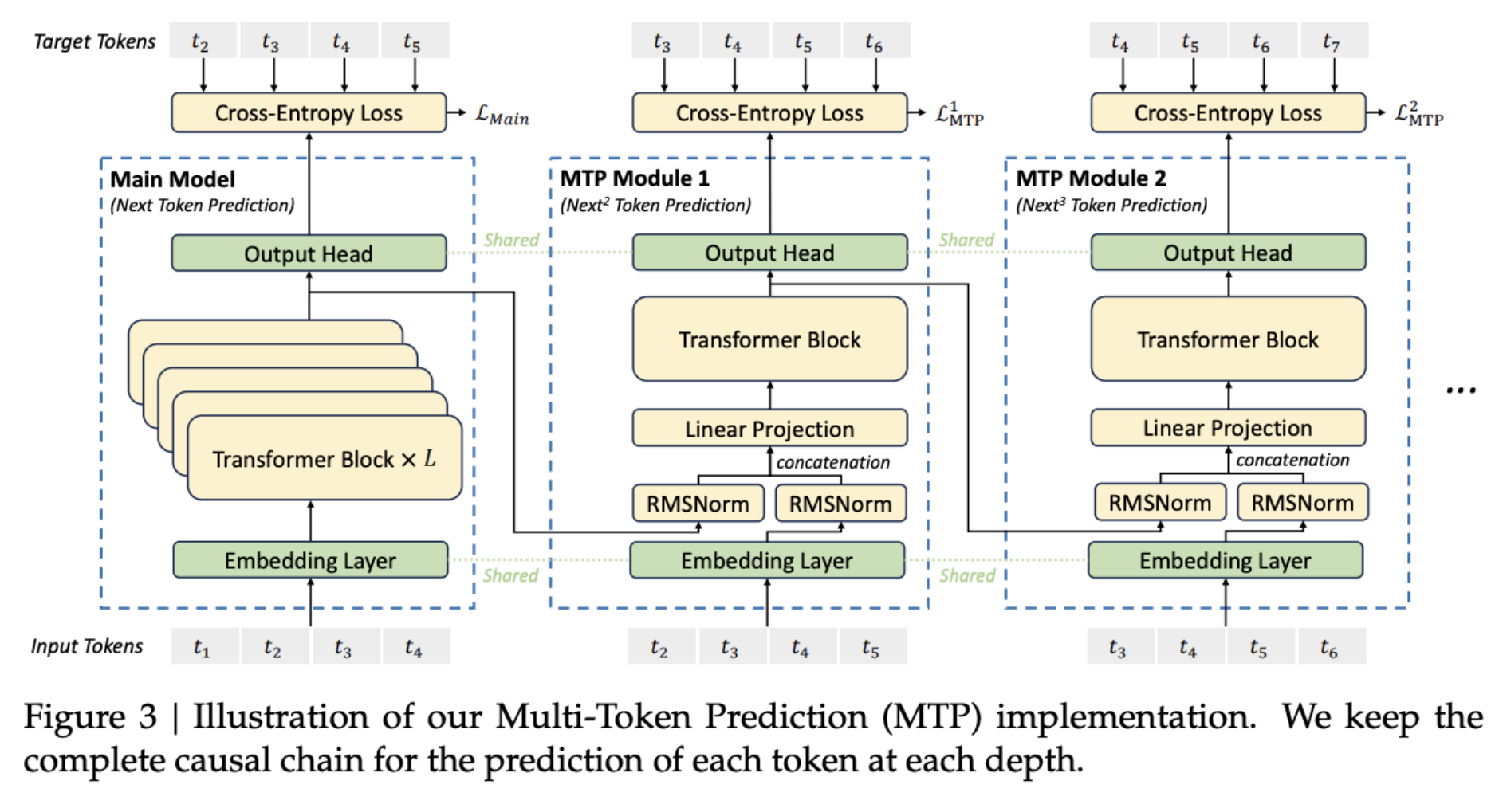
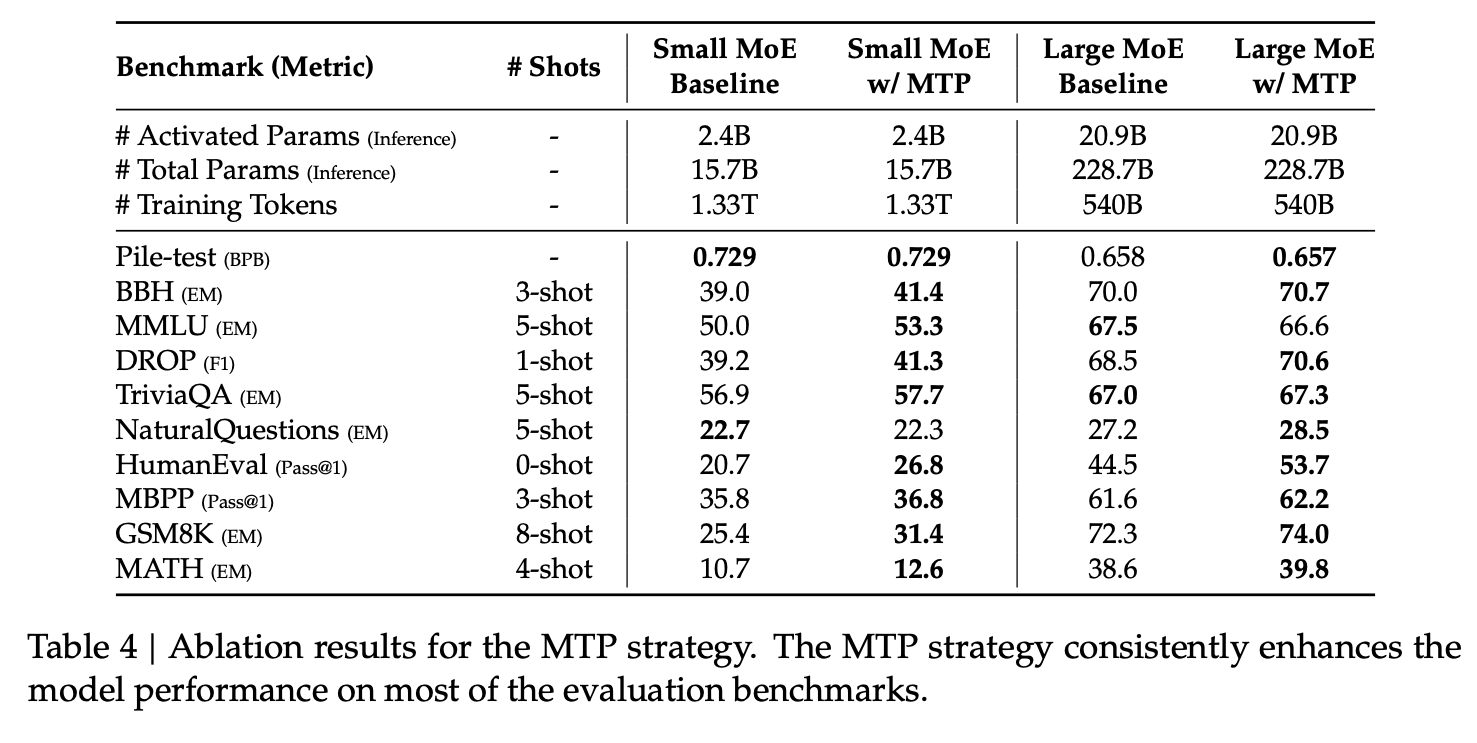
Auxilliary-Loss Free Load-Balancing
Bias Term
The device and expert auxilliary loss introduced in DeepSeekMoe is replaced here, beacuse adding to the loss can affect language model training.
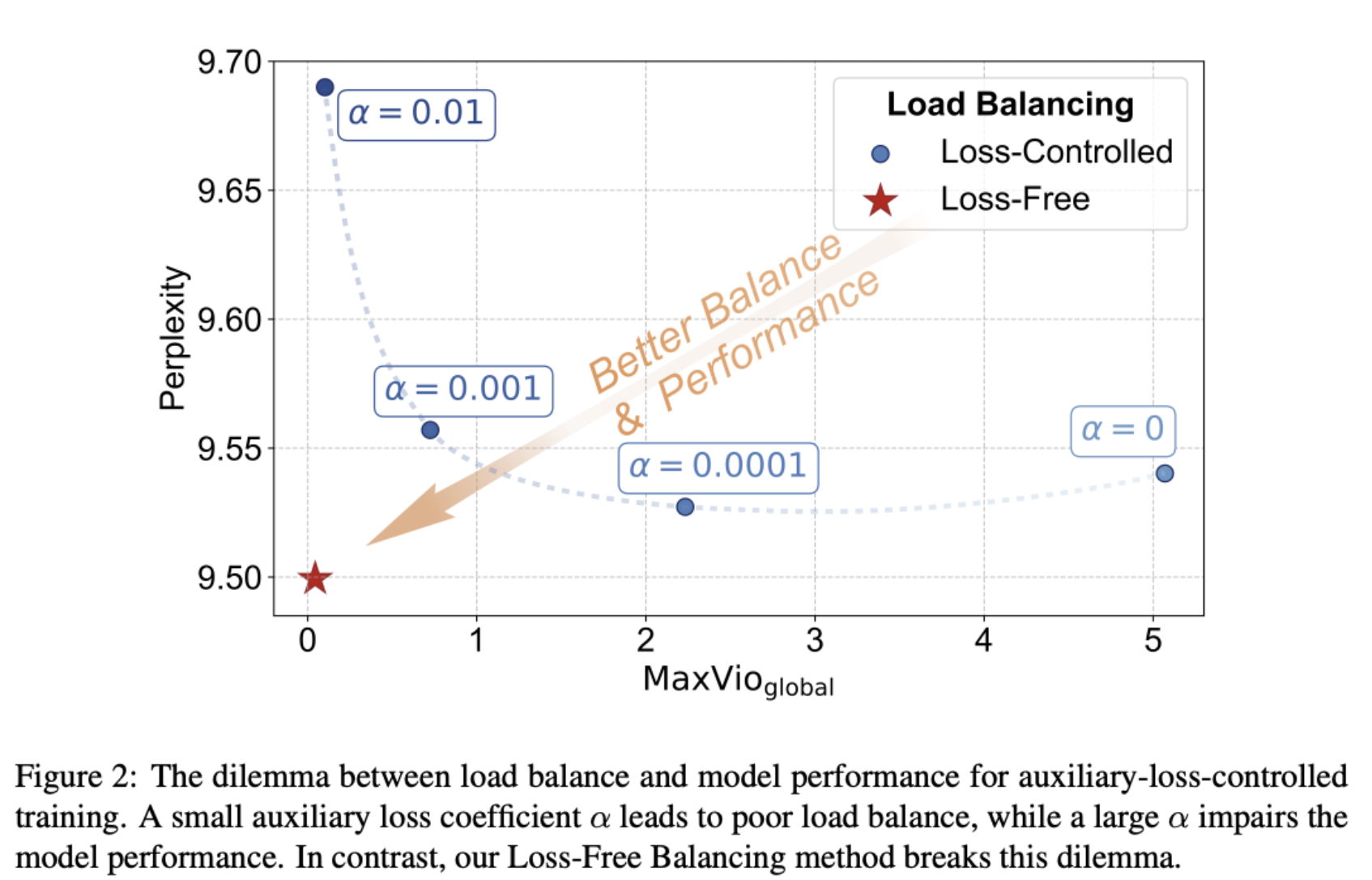
Instead a loss free strategy introduced in Deep’s paper Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts is used. Each expert has a bias value that decreases when overused and increases when underused, that is added to the gate logits. This bias adjusts top-k selection only for load balancing but is not used as part of gate logits otherwise.
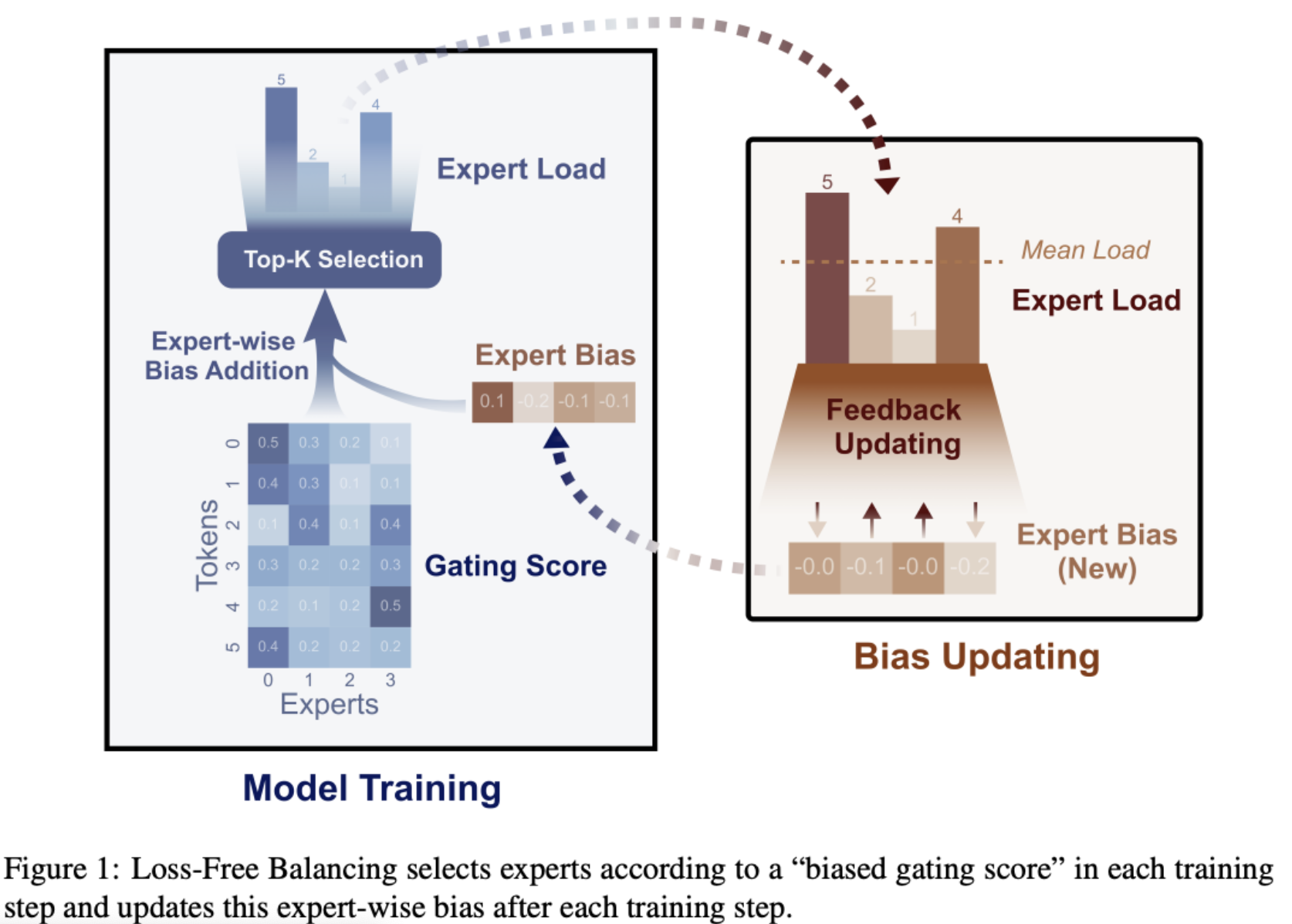
Sequence-Wise Auxilliary Loss
To avoid pathological cases in a batch (eg. while the batch is balanced across experts, all tokens in one sequence uses expert X, where as all tokens in another sequence uses expert Y), a sequence-wise auxilliary loss is used.

DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeekSeek-R1-Zero: First open-source model to show models can learn to reason with RL without SFT
- DeepSeek-R1: A multi-stage training pipeline including some SFT improves readibility and reasoning
- Performance comparable with GPT-4o-0513 and Claude-3.5-Sonnet-1022
- Many infrastructure optimizations
DeepSeek-R1-Zero
DeepSeek-V3 base is trained using RL only. Uses GRPO for reinforcement learning (introduced in DeepSeekMath) on DeepSeek-V3-Base
Reward model is rule based checking for accuracy and thinking format. Do not use outcome or process neural reward model because they suffer from reward hacking
Training template: For training they create a simple template that instructs the base model to first produce a reasoning process, then present the final answer. They keep constraints limited to this structural format to avoid content-specific bias. But the models have an “aha” reasoning moment on their own.
DeepSeek-R1-Zero shows consistent improvement during RL training, with its AIME 2024 pass@1 close to OpenAI-o1-0912, and surpassing OpenAI-o1-0912 when majority voting is used.
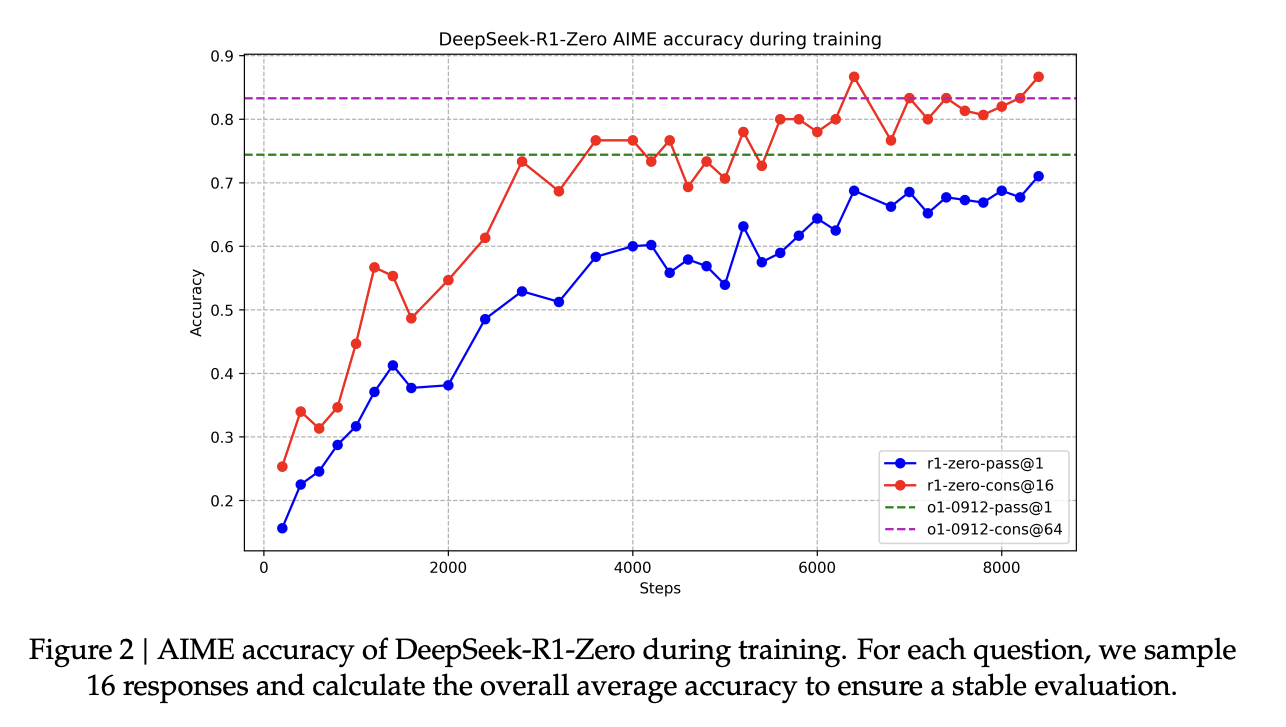
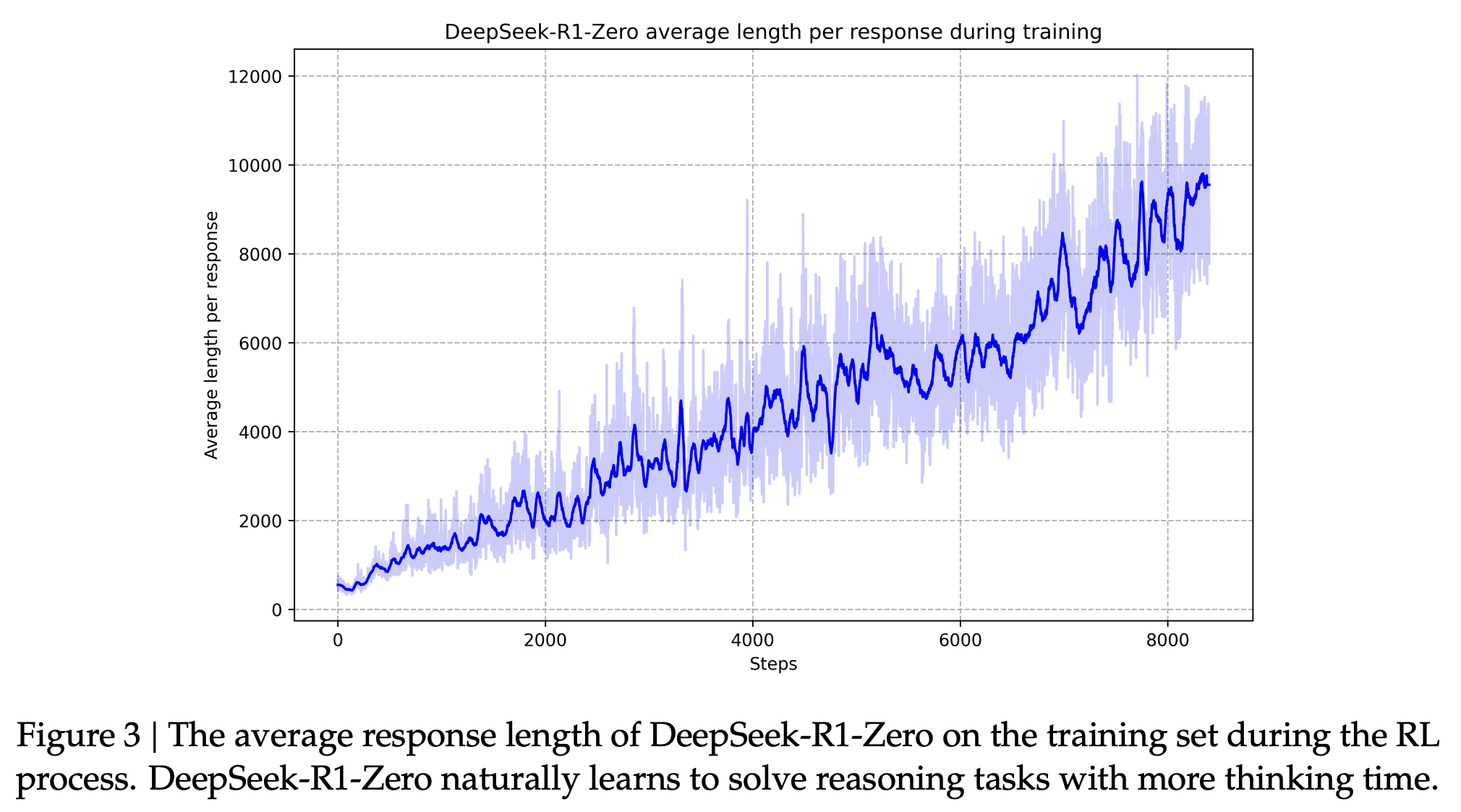
DeepSeek-R1-Zero’s improvement is intrinsic, driven by extended test-time computation. By generating more reasoning tokens as training progresses, it naturally refines its problem-solving ability for complex tasks.
See an example below of the model learning to revisit and reevaluate its previous steps with a long thinking chains. The exploration of alternative approaches toproblem-solving arise spontaneously through the RL process

However, DeepSeek-R1-Zero faces limitations of readability
DeepSeek-R1
Training Pipeline
Multi-stage training pipeline for improved readibility and reasoning patterns
- Step 1: Some “cold-start” reasoning oriented SFT data collected from DeepSeek-R1-Zero with some human post-processing. DeepSeek-V3-Base is supervised fine-tuned on this data to create data_ckpt_1
- Step 2: Reasoning oriented RL-GRPO on data_ckpt_1 is to create a data_ckpt_2.
- Step 3: When RL converges, use rejection sampling from data_ckpt_2 to create more SFT data. However, unlike Step 1, this data is just not on reasoning but other general purpose tasks as well. DeepSeek-V3-Base is supervised fine-tuned using this data to create r1_ckpt_1
- Reasoning Data: (600K) There is both reasoning data that can be evaluated using a rule-based reward model, and ones that need a reward model (DeepSeek-V3 is used to determine reward). Chain of though (CoT) goes through filtering, where mixed language, code, long paragraphs, and incorrect chains are removed.
- Non-Reasoning Data: (200K) Eg. writing, factual QA, self-cognition, and translation, with CoT where appropriate.
- Step 4: RL geared towards improving reasoning and alignment (helpfulness/harmlessness). For reasoning uses GRPO with rule-based rewards, and for non-reasoning tasks presumably using GRPO with a reward model.
Results

Education Benchmarks: DeepSeek-R1 outperforms DeepSeek-V3 on MMLU, MMLU-Pro, and GPQA Diamond, especially in STEM subjects.
QA & Document Analysis: DeepSeek-R1 excels in long-context QA (FRAMES) and fact-based queries (SimpleQA), surpassing DeepSeek-V3.
Format Adherence: Strong performance on IF-Eval reflects improved instruction following.
Writing & Open-Domain QA: DeepSeek-R1 significantly outperforms DeepSeek-V3 on AlpacaEval2.0 and ArenaHard, demonstrating better generalization across reasoning and diverse tasks.
Concise Summaries: DeepSeek-R1 are concise and avoids length bias in GPT-based evaluations, averaging 689 tokens on ArenaHard and 2,218 characters on AlpacaEval 2.0, ensuring robustness across tasks.
Limitations
DeepSeek-R1 underperforms DeepSeek-V3 on Chinese SimpleQA, often refusing certain queries due to safety RL. Without safety RL, its accuracy could exceed 70%.
Shown not to be good on embodied agentic tasks compared to proprietary model
Poor performance on the new Humanity’s Last Exam benchmark. Though to be fair, even OpenAI’s new search based research model, DeepResearch, only performs at 26.6% accuracy, the current highest score.