Paper Summary: Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies
Tamanna Hossain-Kay / 2022-01-08
Paper link: https://aclanthology.org/2021.emnlp-main.150.pdf
Authors: Sunipa Dev (she/her), Masoud Monajatipoor (he/him), Anaelia Ovalle (they/he/she), Arjun Subramonian (they/them), Jeff M Phillips (he/him), Kai-Wei Chang (he/him) (UCLA)
Content Warning: This paper contains examples of stereotypes and associations, misgendering, erasure, and other harms that could be offensive and triggering to trans and nonbinary individuals.
Gender in this paper refers to gender identity, which concerns how individuals experience their own gender. Gender identity is broader than the gender binary that is historically normative in Western cultures, i.e., male and female. In English, some ways gender is linguistically manifested using pronouns (eg. binary: he/him, she/her; non-binary: they/them, xe/xem, ze/zir etc.) and gendered words (eg. binary: man, woman; non-binary: transgender, agender etc.)
Unfortunately, there are harmful social biases towards non-binary individuals. These can be reflected and exacerbated by language and language technologies. Summarized below is some of the technical skews against non-binary identities in current language technologies. For further details, especially a discussion on gender, types of gender biases, and the harms associated with bias please read the paper.
Survey on Harms
The authors conducted a survey to understand representational and allocational harm associated with gender bias in three NLP applications in English: named entity recognition, coreference resolution, and machine translation.
Respondents were non-binary individuals familiar with AI. They engaged with each of the three tasks to experiment with potential harms. Summary of answers about potentially harmful outcomes they saw through their experimentation are shown below.
Dataset Skew
Counts
Pronoun usage counts in a broadly used corpus, English Wikipedia text (March 2021 dump) are as follows:
- he: ~15 million
- she: ~4.8 million
- they: ~4.9 million
- xe: ~4.5 thousand
- ze: ~7.4 thousand
- ey: 2.9 thousand
Usage
As shown above, non-binary pronouns counts are much fewer than binary counts. Furthermore, words for non-binary pronouns were mostly not even used as such. For example,
- Xe is mainly used as an organization
- Ze is mainly used as the Polish word
- Although they is used almost as often as she it used mostly used as the plural pronoun rather than the singular non-binary one.
Non-binary dataset
The Non-Binary Wiki dataset contains instances of meaningfully used non-binary pronouns. However, there’s some shortcomings to this dataset, specifically:
- Doesn’t contain the diversity of sentence structure as Wikipedia. Consists of mostly short biographies.
- Contains mostly Western narratives.
Text Representation Skews
Representational Erasure in GloVe
Reflecting the dataset skew mentioned above, the singular pronouns he and she have neighboring words reflecting their gendered meanings, but the non-binary pronouns xe and ze do not. The closest words to xe are acronyms, and those closest to ze are Polish words.

The possessive forms of binary pronouns his and her also have neighbors reflecting gendered meaning, while the non-binary ones xers and zers do not. Xers even has the negative word “cannibalize” as a close neighbor.

Furthermore, the nearest neighbors for non-binary genders can be derogatory, specifically:
- agender has and genderfluid have as their close neighbour negrito, which means “little Black”
- genderfluid has Fasiq as its close neighbour, which is an Arabic word used for someone of corrupt moral character.

Biased Associations in GloVe
Occupation
Most occupations do not show strong correlation with any words and pronouns associated with non-binary genders.

Sentiment
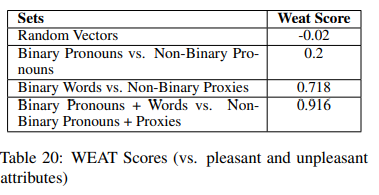
WEAT is a test of bias in word embedding associations. It tests whether target words \(T_1\) are more related to attribute words \(X\) then \(Y\) relative to target words \(T_2\). The WEAT test is used to test the sentiment bias in binary versus non-binary word embeddings.
For sentiment attributes pleasant and unpleasant word sets are used (see below).

For target word sets, \(T_1\) is binary pronouns and proxies, and \(T_2\) is non-binary words and proxies (see below). Proxies are used because as shown above, non-binary pronouns are not well embedded.

A WEAT score of \(0\) is ideal, indicating no-bias. However, as we can see in the table below, the WEAT score for Binary pronouns + proxies vs. Non-Binary pronouns+proxies is 0.916 indicating disparate sentiment association between the two groups.
Representational Erasure in BERT
- Binary pronouns he and she are part of the word-piece vocabulary of BERT.
- However, neo-pronouns like xe and ze are out of vocabulary for BERT, because of their infrequent occurances.
- BERT’s contextual representation should ideally be able to discern between single and plural they, but cannot actually do so with high accuracy.
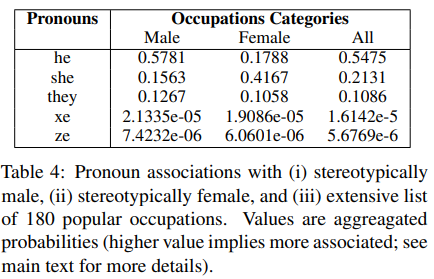
Biased Representation
For exploring association of pronouns with occupations, the following template is used: [pronoun] is/are a [target] .
The target occupations used are from a common-used list of popular occupations, seperated into stereotypically female and male categories. The average probability for predicting each gendered pronoun, \(P([pronoun]|[target]=occupation)\), is computed for each occupation group.
We see that there isn’t a strong relationship between non-binary pronouns and either occupation group.
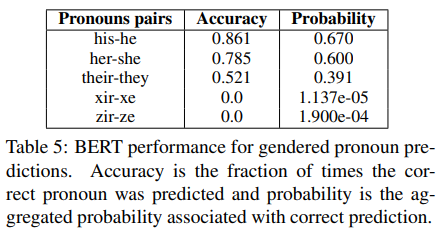
BERT and Misgendering
To explore misgendering, templates such as this are set up: [Alex] [went to] the [hospital] for [PP] [appointment]. [MASK] was [feeling sick].
Words in bold are varied to get a set of templates. Unisex names are chosen from SSN data, i.e., names that are statistically associated with either males or females.
The underlined words are dealt with as a pair. [PP] is a possessive pronoun, which indicates the correct pronoun for [MASK]. [PP] is iterated over, and BERT is tasked with filling out [MASK]. BERT’s ability to fill out [MASK] correctly is evaluated for the following five pairs:
- his, he
- her, she
- their, they
- xir, xe
- zir, ze
From the accuracy figures shown below, we can see that their is a sharp drop is accuracy in BERT correctly predicting binary pronouns versus non-binary pronouns.